概念調査の概念構造モデルを構築する前段階として、テキスト・チャンクの収集を自動で行うことができます。
自由記述プロンプト
ユーザーが指定するカテゴリ(社会調査、市場調査など)で、自由記述プロンプトを使って任意のテキスト・チャンクを収集できます。たとえば、「SNSを利用する上での問題」とか「老後の生活の問題」などといったプロンプトを入力するとアイデア出しができます。あるいは「〇〇分野の新サービス・アイデア」というような直接的にアイデア出しを指示することができます。出力されるテキスト・チャンクにはGTA的な自動コーディングも可能です。作成されたテキスト・チャンクの表はCSVファイルとして保存されます。後のモデル&探索ステップで、テキスト・チャンクが類似性によってグループ化(クラスタリング)され、ネットワーク図で関連付けられるのはKJ法に似ています。
競合製品/サービス
ユーザーが指定するテーマで、市場に現存する製品やサービスの競合分析を行うためのテキスト・チャンクを収集できます。テキスト・チャンクは製品やサービスの概要説明テキストとなり、これをもとに概念構造モデルを構築すると、製品やサービスのコンセプトを多次元空間内でポジショニングすることができます。実際にこれを体験して頂くと、定量データによるポジショニングに劣らないか、あるいは情報の機微をより細かく拾った正確なポジショニングができることがご理解頂けるはです。
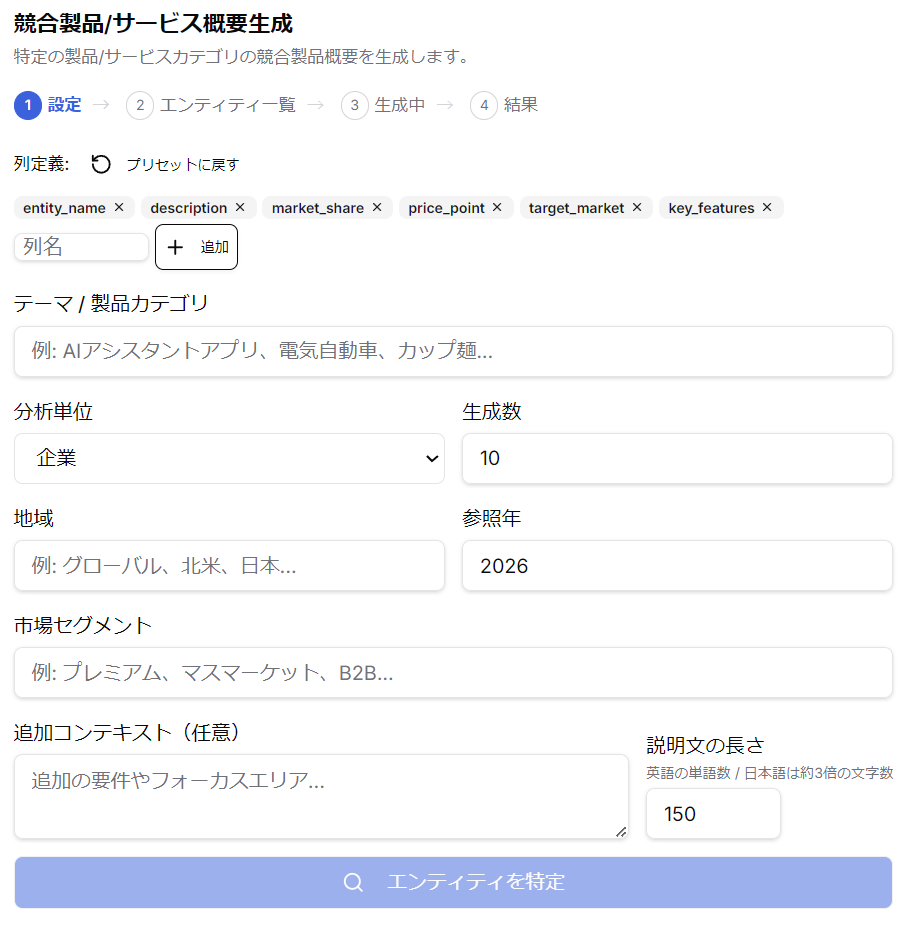
競合コンセプト収集
ユーザーが具体的な説明テキストを入力して、そのコンセプト(アイデア)と競合する実在の製品や事業などに関する説明文を収集します。仮説診断ステップでユーザーが作成したコンセプトを他社のコンセプトと比較するために使用できます。収集されたテキストからモデル&探索ステップで概念マップを作成することで、ユーザーの仮説のマーケットでのポジショニングを事前に調べることができます。
官能評価
食品・飲料などでの官能体験テキストを収集します。もちろんAIが味や香りを直接体験することはできませんので、インターネット上にある公開情報などを学習した知識を使います。ここではAIが持つ知識を利用しますが、これは1つの提案であり、もちろん官能分析の専門家が自然言語で官能体験を記述したテキストを使用されるのも有効かと思われます。従来の官能評価では、主観的な体験を定量的な尺度で表現し直して、主に主成分分析などでポジショニングする方法が用いられてきましたが、自然言語テキストによるポジショニングが今後、代替手法として認知されるようになるでしょう。自然言語の方が繊細なニュアンスを表現することができ、製品間の違いをより細かく分析できる場合があります。
オンライン記事
Google News(無料)、 News API(APIキー要)、 Super API News(APIキー要)などのニュース記事をユーザーが指定するキーワードで検索します。
学術論文
OpenAlex(無料)、Semantic Schalar(無料)、arXiv(無料)、IEEE Explor(APIキー要)からアブストラクトを収集します。
特許情報
USPTO(APIキー要)、Google Patents(APIキー要)から特許情報を検索します。
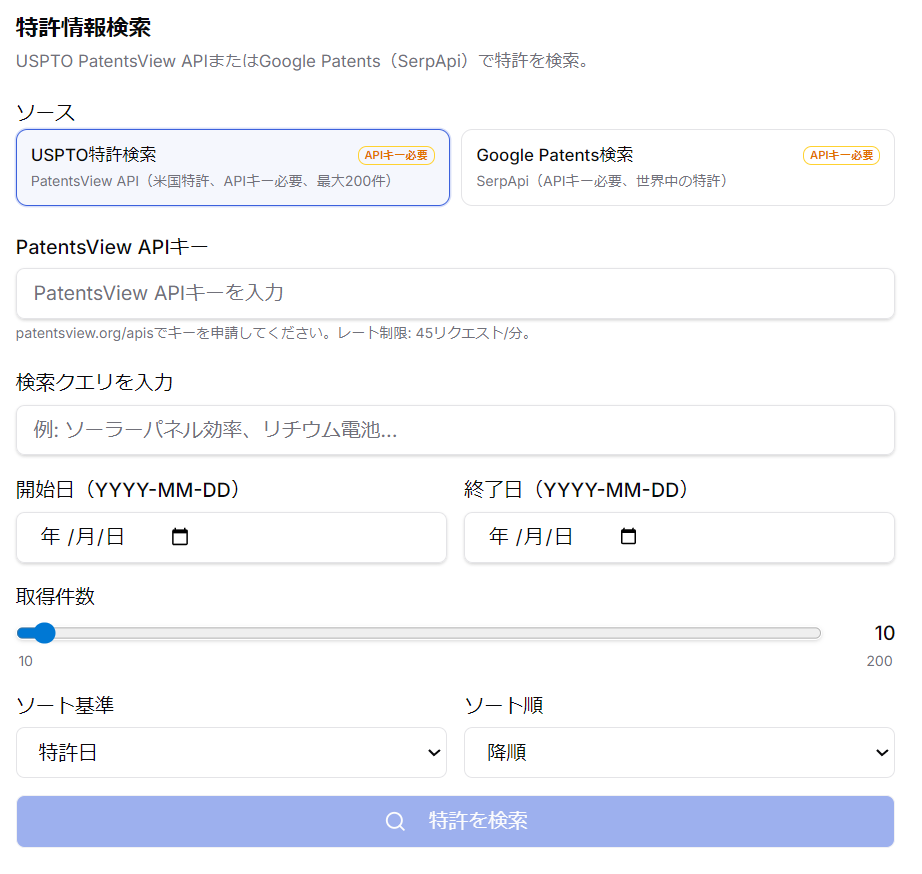
概念抽出
マインドウエアのために文書のテキストから複数種類のテキスト・チャンクやコードで構成された表を作成します。
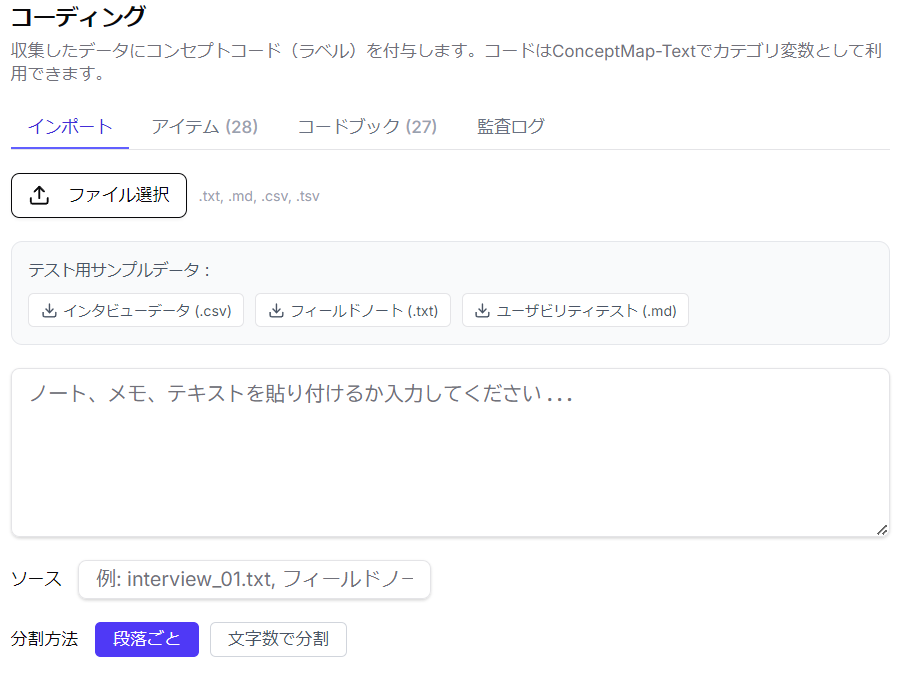
コーディング
インタビューデータ、フィールドノート、ユーザービリティテストなどのデータ(txt, md, csv, tsv)をインポートして、GTA的なコーディングを行うことができます。コーディングはAI支援により自動で行うことが可能です。
ファイル管理
上記で作成したデータをCSVで保存し、不要な行を削除するなどの編集ができます。保存したデータは、モデル&探索ステップでモデル構築に利用します。